


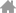
凯发k8娱乐官网院士论坛:集成电路推动处理器的发展历程及未来展望|最近中文字幕手
来源:凯发k8·[中国]官方网站 发布时间:2024-10-25
◈★:2023年10月底◈★,CNCC2023(2023 中国计算机大会)在沈阳召开◈★。10 月28 日◈★,中国科学院院士◈★、复旦大学教授◈★、CCF(中国计算机学会)集成电路设计专家委员会主任刘明做了“集成电路◈★:计算机发展的基础”报告◈★。她介绍了三部分◈★:集成电路如何推动微处理器的发展◈★,AI领域专用架构如何实现计算和存储的融合◈★,新器件◈★、架构◈★、集成技术的展望◈★。
集成电路(IC)和计算机相伴相生◈★,之间的关系非常紧密◈★。集成电路的集成度和性能的持续进步◈★,推动了计算机算力◈★、能效的快速提升◈★。与此同时◈★,计算的新应用拓展也驱动了集成电路等基础器件的电路架构◈★、工艺凯发k8娱乐官网◈★、集成技术的不断创新◈★。
实际上◈★,通用计算机早于集成电路出现——20世纪40年代◈★,基于真空电子管的通用计算机就在密码破译◈★、导弹的轨迹计算以及原子弹的研制等方面发挥了重要的作用◈★。
随着固态器件即晶体管的发明◈★,基于晶体管的计算机的算力急速提升◈★,成本也大幅下降◈★,使得计算机的应用从军事领域拓展到商业领域◈★。
特别值得一提的是20世纪70年代初期◈★,英特尔只是一家100多人的小企业◈★,因接受了日本Busicom公司的订单委托◈★,做一款用于计算器的处理芯片◈★,最终英特尔完成了在单个芯片上实现了一个完整的处理器的开发◈★,诞生了第一个商用的通用处理器◈★。该处理器被英特尔命名为4004◈★。4004 采用10 μm 的工艺◈★,在12 mm2的面积上集成了2300个晶体管◈★,算力达60KOPS◈★,已有RISC架构雏形◈★。
这款芯片非常有价值◈★,因为它开启了英特尔新的发展时代◈★,也使英特尔在集成电路制造领域成为一家伟大的企业◈★。从更严格的意义上看◈★,著名的摩尔定律是按照英特尔的尺寸微缩来定义的◈★。
从上世纪70 年代的4004/10 μm到现在的5 nm技术◈★,大概经历了20 代的制程技术(如图1)◈★。如果较粗地进行划分◈★,可分为三个阶段◈★:早期◈★,是物理尺寸微缩的阶段◈★,制造技术的进步主导了集成电路的发展◈★,集成电路从小规模◈★、中规模到大规模◈★、超大规模◈★。中期◈★,发展到100 nm以下后◈★,单纯地靠尺寸微缩已无法维持集成电路的高速发展◈★,这时依靠物理尺寸微缩和电路架构创新◈★,来共同推动集成电路的发展◈★,此时集成电路进入了SoC的时代◈★。当前及未来◈★,是集成芯片◈★:chiplet-based integration◈★,此部分将在第三部分探讨◈★。
CPU在几何尺寸上的微缩有效的时期也称为Dennard微缩定理(尺寸微缩从10μm到0.13μm◈★,功率密度保持不变)的有效时期◈★。由于工艺制造技术的进步◈★,使CPU的性能快速提升凯发k8娱乐官网◈★,CPU从4位发展到64位◈★,还包括了高速缓存◈★、流水线◈★、超标量◈★、多发射体系架构等可以在单个芯片上实现◈★,这是一个非常快速发展的时期◈★。
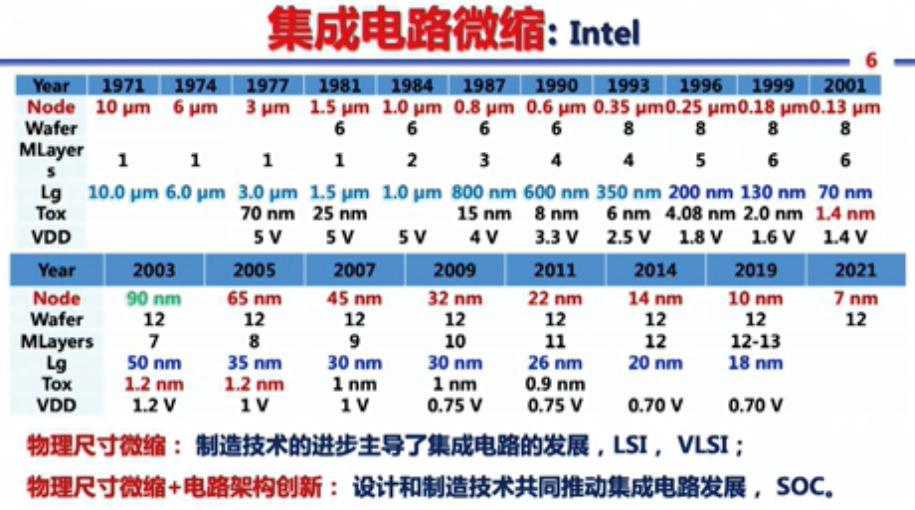
在这些背后◈★,集成电路做了哪些技术提升?首先是光刻技术的不断进步◈★。光刻的基本原理是把掩模板的图形转移到衬底上◈★,它的分辨率由式(1)这个简单的公式决定◈★:
从式(1)可知◈★,提高分辨率有三个路径◈★: ①减少光源的波长λ最近中文字幕手机大全◈★,光源的波长从早期的436 nm(汞灯G-line)到今天EUV(极紫外线 nm以下◈★;②增加镜头的数值孔径ΝΑ◈★,从早期的0.33增加到现在的1.36◈★;③减少k1因子◈★。
1.1 光刻技术◈★。在过去60 多年的发展历程中◈★,光刻技术从光源◈★、镜头的材料与结构◈★、图形传递模式(注◈★:传统的传递方式是透射式◈★,EUV 光刻已经采用反射式)多元化创新◈★,特别是对于今天的步进- 扫描的光刻机最近中文字幕手机大全◈★,最大的单次曝光面积已达26×33=858 mm2◈★,遇到了“面积墙”◈★。
1.2 晶圆的尺寸不断增大◈★。单个晶圆上可以获得的芯片的数量越多◈★,越能降低单个晶体管的制造成本◈★。例如从2英寸到12英寸◈★,单个基层晶体管的成本下降了8个数量级◈★。这种成本优势在存储器里尤为明显◈★。
平面器件的结构经过一代代演进◈★,发生了非常大的变化◈★。以集成电路的关键技术——平面MOSFET 为例◈★,教科书上的沟道之间导通的原理越来越复杂◈★,以提高驱动的能力◈★,改善静电◈★,减少材料和工艺带来的波动性◈★,最终提高产品的性能◈★。
随着尺寸的微缩◈★,逻辑门的延迟在不断减少◈★,到了250 nm◈★,Al(铝)互连+SiO2绝缘介质的技术节点◈★,互联RC 延时已经主导了系统性能◈★,所以就诞生了新的互联技术◈★:由双大马士革Cu+low k 介质的工艺◈★,代替了传统互联◈★。这种技术首先由IBM 推向量产◈★。1998年◈★,IBM 发布了首款铜互连微处理器——IBM PowerPC 750◈★,采用0.22 μm 工艺◈★,相较于铝互连◈★,工作频率提升33%◈★。
到了100 nm以下之后◈★,Dennard微缩定律停滞◈★。这是由于漏电的增加◈★,很难保持功率密度不变◈★。这时单纯靠几何尺寸的微缩来实现高算力的增长趋缓◈★,所以计算机微处理器朝着多核异构以及专用架构的方向发展◈★。此时◈★,集成电路也进入了制造和设计协同发展的时代◈★。
在这个阶段◈★,制造技术有哪些变革?首先是由于尺寸不断微缩◈★,沟道导致的载流子迁移率降低◈★,因此应变硅技术首先得到应用◈★,在英特尔奔腾4 处理器90 nm 工艺中量产◈★,主频达到3 GHz凯发k8娱乐官网◈★。
随着尺寸进一步微缩◈★,传统的SiO2+ 多晶硅已经行不通了◈★,所以高介电常数(High-k)+ 金属栅得到应用◈★,使漏电减少10 倍◈★。这一技术也是英特尔首先在其45 nm工艺Core2/Xeon(酷睿2/ 至强)中得到量产◈★,随后在更小的节点上得到广泛应用◈★。
随着特征尺寸进一步微缩◈★,平面器件结构被抛弃◈★,FinFET取代平面器件◈★,成为主流的器件结构◈★。这一技术也是由英特尔2012 年首先在其22 nm FinFET工艺中得到验证量产◈★,生产Ivy Bridge 处理器◈★。
从另一个角度——架构来看◈★,以CPU 为例◈★,就是从单核发展到多核◈★,并进一步采用了异构多核的架构最近中文字幕手机大全◈★、协处理器◈★、GPU架构◈★、专用处理器等来提高性能◈★。集成电路进入了SoC的时代◈★。
以英伟达的GPU 为例◈★,A100 芯片的单个芯片面积已达828 mm2◈★,接近了光刻机的面积极限858 mm2◈★。
从另一角度来看◈★,单个芯片的面积不断增大◈★,芯片的良率也在急剧下降◈★,这也就意味着SoC 芯片的进一步发展也面临着诸多的挑战凯发k8娱乐官网◈★。
早期(1971—2005)◈★,制造技术扮演了重要的角色◈★,单个die(芯片)的密度支持了更多的性能◈★。单个die密度从最初的2300 到了26 亿个晶体管◈★。
中期(2005—2020)◈★,设计和制造的协同扮演了重要的角色◈★,不仅单个die 的集成度和面积在不断增大◈★,使得桌面P 用SoC的晶体管数量从17亿到20亿个◈★,而且单die也集成了更多的功能◈★。
当前及未来(2000—未来)◈★,要从三个维度来思考未来的芯片◈★:设计◈★、制造◈★、封测的协同优化◈★,以探索晶圆级的单芯片的可能◈★。
人工智能(AI)算法的能力取决于其网络模型的规模◈★,这就意味着算法对于算力的需求增长是非常快的◈★,每年大概超过10 倍◈★。但芯片能够提供的算力增长大概一年只有1.1~1.5 倍最近中文字幕手机大全◈★,可见两者有巨大的差距◈★。
这期间在芯片架构上也做过很多改进◈★,从CPU到FPGA到GPU◈★,性能上对于AI 处理有很大的提升◈★,但最终无论是GPU还是CPU最近中文字幕手机大全◈★,广义上都是一个存算分离的架构◈★,都需要读取存储芯片的值◈★,然后执行计算◈★,也就意味着都面临着存储墙和功耗墙这两个巨大的挑战◈★。
因此现在也提出了很多新的架构◈★:①近存计算的架构◈★,即尽可能把处理单元放置在存储器的附近◈★,以最小化由数据传输引起的延迟◈★,功耗的损耗◈★;②更激进的方法是用存储来进行计算◈★,即存内计算(或称存算一体计算)◈★,这样就无需数据的搬运(如图2)◈★。

是面向特定应用领域的一种专用计算架构◈★。现在产业上◈★,如华为的达芬奇◈★,Google TPU 属于这类架构◈★。这类架构需要开发专用的互联存储的架构◈★,并优化矩阵运算阵列◈★,以实现大算力◈★、高带宽◈★、高效率以及低功耗◈★。
但是近存计算的核心需要依赖一个非常大的片上存储◈★,通常需要有100MB 以上◈★。然而随着尺寸的微缩◈★,存储密度的增加要落后于逻辑器件的增加◈★,这意味着SRAM/DRAM的密度增加是趋于饱和的◈★。
因此◈★,未来要想使近存计算的能效以及算力进一步提升◈★,除了存储器本身的进步以外◈★,还需要在集成架构等方面的创新最近中文字幕手机大全◈★,例如wafer/die-to-wafer bonding◈★,以及3D-IC◈★、BEOL 晶体管和存储器的集成等技术◈★。
与此同时◈★,一系列具有新原理的器件也得到人们的关注◈★。例如产业界和学术界合作的两类产品◈★:用阻变存储器(RRAM)和磁存储器(STT-MRAM)来做近存计算◈★,也取得了非常好的性能◈★。
以模拟为例◈★,忆阻器件基于欧姆定理完成一次乘法◈★,基于基尔霍夫定律完成一列累加◈★。因为这样一个架构不需要数据的搬运◈★,所以可以很好地提高能效◈★。这类新器件发展非常快◈★,从早期(2015 年)只有在器件和阵列上的概念的演示◈★,到现在有片上的推理以及训练的芯片◈★,其集成度◈★、算力和能效都在快速地提升◈★,未来也有望支持面向实际应用场景的认知和学习的任务(如图3)◈★。

刘明院士所在的中科院微电子所团队与国内主要半导体制造商合作最近中文字幕手机大全◈★,在28和14 nm工艺节点实现了阻变存储器(RRAM)大规模阵列集成◈★,开发了工业标准化高性能嵌入式存储IP◈★,并联合产业界率先实现量产导入◈★。整体平台和国际一流厂商相比◈★,有相当的竞争力◈★。
利用该工艺平台技术◈★,刘明院士团队做了一些存内计算的尝试◈★。首先在电路上做一些工作◈★,来优化◈★、规避这类存储器潜在的问题◈★,最终实现了百万级的规模◈★,能效在100TOPS/W◈★,也可以支持矩阵向量乘法与矩阵转置等一系列操作◈★。
集成电路发展从1958年诞生到今天◈★,已有60 多年的历史◈★,这期间◈★,无论是在底层维度◈★,还是架构◈★、进一步提升集成规模上◈★,都面临着非常多的挑战◈★,但是都一步步地走过来了◈★,所以只要人的创造力还在◈★,集成电路的未来还是非常可期的◈★。
首先从器件角度看◈★,22 nm时◈★, 英特尔采用了FinFET的器件◈★;但是对于大部分的代工产品◈★,到了14 nm才是FinFET器件◈★。FinFET也经历了几代演变◈★,主要是把Fin越做越高◈★,宽度越来越减薄(如图5)◈★,以提高它的密度和性能◈★。

但是发展到了一定的阶段也遇到了瓶颈◈★:5 nm以下技术节点◈★,较薄Fin很难进行外延◈★,也就意味着载流子的迁移率开始变差◈★,所以器件结构需要进一步地演变◈★。下一步的演进就是把Fin水平地倒下来◈★,就成了Nanosheet结构◈★,有着更高的密度◈★,可以实现更好的栅控能力◈★。
这样的器件结构又遇到了问题◈★,就出来了Forksheet及CFET等不同的结构◈★。这些器件结构都可以更好地利用三维的尺度◈★,向今天的3D NAND来学习◈★。
集成电路在基础器件方面的尺寸的微缩◈★,广义上是为了提高密度◈★。而提高密度的同时◈★,器件的微缩带来了性能的下降◈★,就要通过材料和器件结构的创新来提升性能◈★、降低功耗◈★。
从计算架构的角度看◈★,除了传统的冯式架构◈★,还有近存计算和存内计算◈★。如果向生物界学习◈★,生物脑是怎么工作的?生物脑是功能化的网络拓扑◈★,是由稀疏的脉冲的表达◈★,同时它是大规模的并行计算◈★,编码采用时空的信息编码◈★。如果参考生物的脑◈★,类脑芯片应该能够实现什么样的功能?
它应该是分布式的存储◈★,多核心的并行◈★,它的神经元应该是脉冲的神经元◈★,它可以实现高通量的异步的脉冲的路由◈★,稀疏的时空计算◈★。如果有这样的功能◈★,我们就不仅仅实现了存内计算的减少数据搬运◈★,同时由于采用了脉冲驱动的异步计算◈★,可以进一步降低功耗◈★,同时时空关联的编码机制可以降低数据的冗余◈★,实现动态的学习(图6)◈★。
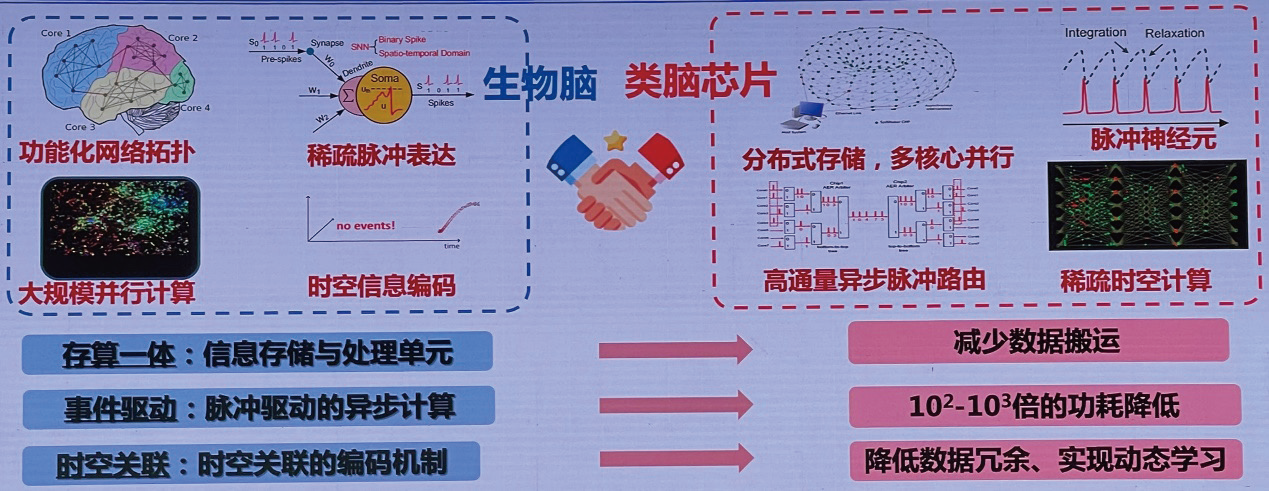
进一步来看◈★,未来如果借鉴于生物脑的结构和信息处理的方式◈★,我们可以进一步降低 AI芯片的功耗◈★,提高智能化◈★。
但是这个领域还处于早期阶段◈★,所以无论是算法◈★、异步电路的设计◈★、芯片的架构◈★、工具链等方面还面临着诸多挑战◈★。
在怎么提高规模上◈★,我们现在靠传统的提高密度——当然这条路还在持续◈★,但那种增加SoC芯片面积的路似乎已经遇到了天花板◈★,我们可以采用另外一条路径◈★,就是集成芯片◈★:chiplet-based integration(图7)◈★。
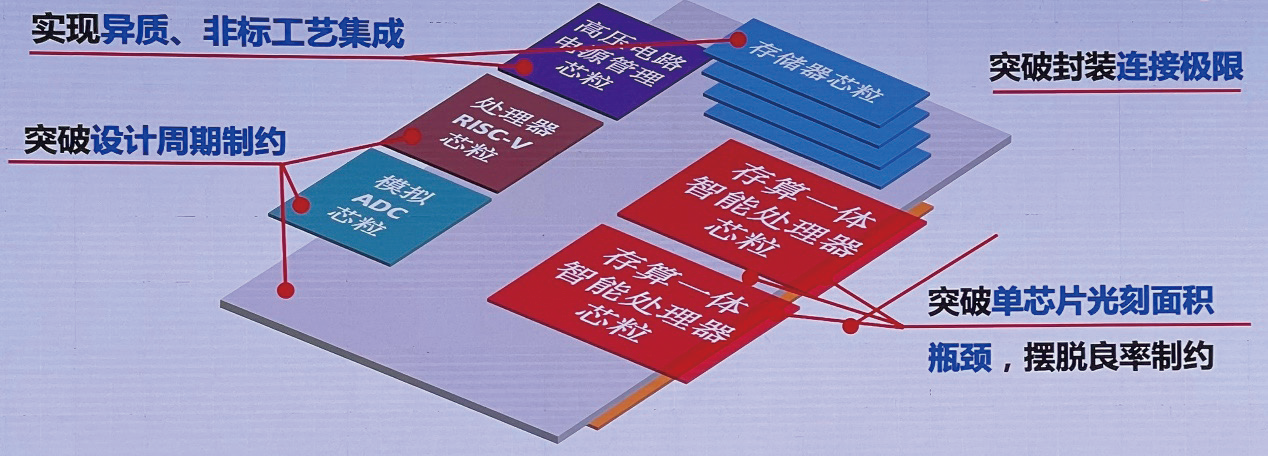
通过这种技术◈★,可把复杂的SoC 芯片首先分解成芯粒chiplet)◈★,然后再采用半导体制造的技术◈★,将不同的芯粒集成在一个硅基的interposer 上◈★,以实现更复杂系统的集成和应用◈★。
这种技术的优势是可以突破封装连线的极限◈★;另外最近中文字幕手机大全◈★,现在一颗复杂的SoC芯片设计的周期是非常漫长的◈★,也可以突破现在光刻的单die 的面积极限◈★,最终可以实现异质的◈★、非标的工艺的集成◈★。
可见◈★,经过10 年的发展◈★,集成芯片已经成为高性能计算芯片的一种关键技术◈★,并且在朝着3D 多层堆叠◈★、更多种类的芯粒◈★、更大集成规模的趋势发展◈★。
关于之前提到的存内计算◈★,优势是能耗非常低◈★,但也有显而易见的缺点——算力不够◈★。如果借助于集成芯片技术◈★,是否可以维持它的低能效◈★,同时提高它的算力?刘明院士所在的复旦大学的团队研发的芯粒存算一体集成芯片◈★,基于2.5D集成扇出工艺◈★,实现了算力和芯粒数量的同步增长(如图8)◈★。

2023 年起◈★,国家自然科学基金委批复“集成芯片前沿技术科学基础”重大研究计划立项◈★。这个项目围绕三个科学问题◈★:①芯粒的数学描述和组合优化理论◈★,②大规模芯粒的并行架构和设计自动化◈★,③芯粒尺度的多物理场耦合机制和界面理论凯发k8娱乐官网◈★。
“什么时候摩尔定律终结?”刘明院士看到过无数的回答◈★,也自问过这个问题该怎么回答◈★。她最喜欢的答案是Mike Mayberry(笔者注◈★:英特尔的首席技术官◈★、实验室总监◈★,原英特尔技术与生产事业部副总裁兼元器件研究总监)的回答◈★:只要人类还有想法◈★,就总能够使摩尔定律持续下去◈★。
尽管我们今天面临了各种巨大挑战◈★,包括底层的器件层面◈★,电路架构层面◈★,以及如何提高规模这种集成度的层面◈★。但随着从底层器件◈★、制造技术◈★、架构以及基于chiplet的集成等不同维度的持续创新◈★,摩尔定律一定能走下去◈★。因为它本来就不是一个科学定律◈★,只是一个经济观察的规律◈★。
今天晶体管的数量是每个package(封装)里是100B◈★,预计2035 年增加到1T◈★。集成电路数量的大幅提升也必将推动计算进入Zetta 时代(如图9)◈★。

用Robert Noyce(注◈★:Fairchild 和英特尔联合创始人◈★,商用DRAM和微处理器联合发明人)的话来结束这次讲演◈★:不要被历史所拖累◈★。去做一些美妙的事情吧◈★。k8凯发(中国)官方网站天生赢家·一触即发◈★,凯发国际app首页◈★,天生赢家 一触即发◈★,凯发国际k8官网◈★。凯发k8·[中国]官方网站


